FAE Notes
Environment Setting¶
Q: What is the Docker's minimum memory requirement?
A: The minimum memory required is 8G. Besides, we recommend that you use the docker provided by SigmaStar.
Q: How to upload and run the Python 32-bit library over a 64-bit server?
A: The Python3.5 32-bit package is located in /root/.Python3.5-32 under the docker environment. /root/bin/python32 is the soft link of /root/.Python3.5-32/bin/python3.5. By adding /root/bin to the path and exporting PATH=/root/bin:$PATH, you should be able to run 32-bit Python using Python32.
Q: I loaded the v1.5 docker but it did not go into operation, why?
ryanlu@ubuntu:~/IPUSDK/docker$ docker image ls REPOSITORY TAG IMAGE ID CREATED SIZE sgs_docker v1.5 0cf7dc563a58 5 weeks ago 19.3GB ryanlu@ubuntu:~/IPUSDK/docker$ docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES dd90d00ded32 e6a2cf5b71ab "/bin/bash" 4 months ago Exited (0) 1 second ago SGS_V1_16.04 docker rm SGS_V1_16.04 Then rerun ./run_docker.sh.
A: Note that the container will not necessarily be cleared when the image is deleted.
Operators Restrictions and Support¶
Q: What are the restrictions of Mul and Add operators?
A: Mul and Add operators are operators that multiply and add corresponding positions. The two operators would work normally if the shape of the data on both sides is less than or equal to 4, the shape of B is the same as the shape of A, or the number of A is equal to the number of C.
For example, you can do Mul and Add operations against a shape with the format 1, 272, 272, 8 and 8.
Q: Are absolute coordinates or relative coordinates used for NMS post-processing?
A: NMS uses relative coordinates between [0,-1].
Q: Is there any problem with the use of Sum followed by Div?
A: Due to hardware restriction, the Tensor output Sum operator cannot be used as the second Tensor of Div operation.
This is because the second Tensor of Div operation in this case will become a variable (thereby making quantization impossible and accuracy not guaranteable). On the other hand, since the SigmaStar hardware does not contain a floating-point calculation unit, there will be a huge loss of accuracy in the process of division quantization.
Q: Are there any limitation concerning magnification on the operator?
A: For the resizeBilnear operator, the magnification should be 8 times. This multiple refers to the multiple of H expansion multiplied by the multiple of W expansion. For example, if H is expanded by 3 times and W is expanded by 2 times, then the total expansion is 3 * 2 = 6 times, which satisfies the magnification limitation and can therefore run on the hardware of IPU without any problem.
Q: How to implement relu6?
A: relu6 is implemented using clip(0,6).
Q: Is reduce_max supported?
A: Yes, this operator is supported.
Q: Is there any limitation concerning matmul?
A: If the following condition is met, it will convert to full connection (full connection is supported if tflite is set to fullyconnected).
Condition: The second parameter is a const.
tf.matmul (a, b, transpose_a=False, transpose_b=False, adjoint_a=False, adjoint_b=False, a_is_sparse=False, b_is_sparse=False, name=None)
Note that matmul operation is not supported if both a and b are variables.
Q: Is it necessary to keep the inner dimensons of the two inputs of the Mul operator equal?
A: Yes. For example, in case the two inputs of the Mul operator in the model are defined as split:2 (shape[50,50,3,1]) and split:3 (shape[50,50,3,80]), in which the inner dimensions are not equal (one being 1 and the other being 80), you will not be able to perform the Mul calculation. To solve this, you can either replace the operator or set the inner dimensions of the inputs to be equal and then re-convert the model.
Note: The point here is, the input dimensions of the Mul operator must be equal when you convert the model from .pb to .tflite. If the .pb model is conformant while the .tflite model is not, try to generate a .tflite model which contains an inner dimension equal to that of the .pb model, because .tflite model is actually the model input to the IPU_SDK toolchain. If you input the .pb model, the ConvertTool will convert the .pb model into .tflite. That's why you need to ensure the .tflite model meets this requirement.
Below are some more details on the equal-inner-dimension requirement:
-
Q: Is it necessary to make the shapes of the input tensor equal to run Mul operation?
For instance, suppose we have one tensor and one scalar. Is it required that the shape of the scalar be made equal to that of the tensor to run the Mul operator?
A: There are three types of inputs for the Mul operator:
- [x,y,j,...,K] * [K]
- [x,y,j,...,K] * scalar
- [x,y,j,...,K] * [x,y,j,...,K]
The last type is the one to be implemented in the case here. So equal inner dimension is mandatory.
Q: Why does the calibration process fail when NMS operation is added?
A: Please go through the following checkpoints to see if: 1. the input of the post-processing model is consistent with the output configuration of the backbone 2. the float.sim model simulator after concat_net is correct 3. the input_config.ini file configuration and the calibrator command are correct.
Note: Please pay attention to the NMS limitations below.
The input dimension of NMS operator only supports two-dimensional input like [1,22743]. Please refer to PostProcess_Unpack and TFLite_Detection_NMS of the Post-processing section to implement custom post-processing operator.
Q: I have problem implementing the LeakyRelu operator, why?
A: Please check if the operator is implemented without conforming to the definition of mathematical formulas; models with non-standard usage are not supported.
For example, the alpha coefficient of the LeakyRelu operator in the model should be in the range of (0,1) pursuant to the LeakyRelu mathematical formula. If the alpha parameter value in the model is larger or smaller than 1, modify it.
Q: Is efficient-net function available?
A: Some simple models support efficient-net function. If this function is required, please provide your model to us for debugging.
Q: Is there any restriction concerning use of the split function?
A: There must be two outputs when split is run, even if the second output is not used.
For example, if the split_num of the network is set to 2, but only one output is generated, an exception will occur.
Q: Does the Pudding platform support ResizeNearestNeighbor operator?
A: The Pudding platform currently does not support ResizeNearestNeighbor operator. This operator is supported by Tiramisu platform only.
The accuracy will be much lower after ResizeNearestNeighbor.
You can confirm this from the DebugDump result:
19 27.detector_yolo-v3-tiny_ResizeNearestNeighbor.xx.output0 OP_TYPE: RESIZE_NEAREST_NEIGHBOR MSE: 2.473601 COS: 0.480970 RMSE: 3.932084 **** OVER threshold!!!! ****
If you do not intend to replace the platform used, we suggest that other operators such as reshape and tile be used instead.
Q: Why does Memory Error appear after the simulator is executed a certain number of times?
A: This problem depends on your local environment. Please check if the memory space is insufficent or your code execution process has encountered any problem. This has nothing to do with the model itself.
Note: Let's take "imgs_gen = img_gen = utils.image_generator(img_list, preprocess_funcs, norm)" as an example. Since imgs_gen is by itself an image iterator, there is no need to put it in the for loop. Instead, you can directly run calibrator/simulator.py, which supports multi-processing. In this way, there will be no more problem even if you run out of memory space.
Q: Is there any exception on the IPU Converter?
A: The IPU Converter does have the following exception: presently Mace does not support Caffe op type ReLU6.
Q: Does Caffe model support ReLU6 in SGS_IPU_SDK?
A: In Caffe prototxt, the ReLU6 operator is not officially supported yet; if ReLU6 is required, you can add it by this github threough https://github.com/chuanqi305/ssd.
To run ReLU6 operator in Caffe model, you should modify the ReLU6 in model.prototxt to Clip and set min=0.0, max=6.0.
Q: What is the limitation on hardware design of depthwise convolution?
A: For Pudding platform, the filter size can only be 3x3 (height x width) when the depthwise filter is dynamic.
If this limitation is exceeded, you will not be able to run depthwise convolution on the Pudding platform even if the model is successfully converted.
Note: The convolution of the conv layer with variable kernel weight in the model is a deptwise convolution rather than a normal convolution.
The Tiramisu platform supports filter sizes of 3x3, 6x6 and 9x9 (height x width).
Q: The input_config.ini file with input_formats = RAWDATA_S16_NHWC encountered a configuration problem. How can I deal with it?
A: If input_formats = RAWDATA_S16_NHWC in the multi-input model input_config.ini, mean_red, mean_g, mean_b, and std_value should be commented out.
Q: Is there any special attention I should pay to the use of Efficientdet model?
A: If the model is relatively large, make sure that it does not exceed the maximum allowed size of 10000 tensors.
Conversion Problems¶
Q: Is there any restriction regarding conversion of Onnx model?
A: For Onnx model, please execute Onnx runtime first. If there is no problem with the Onnx runtime, start the conversion then.
Q: What is the execution environment best recommended for Onnox?
A: The execution environment currently recommended for Onnx model generation is Onnx version 1.17.
Q: Why can I convert the model to an SGS float model when there is an unsupported operator?
A: If inference is available under IPU SDK docker environment, the IPU SDK would have a higher capability of inference at board side.
In the process of conversion, the operator will be registered according to the TensorFlow operator list. Since only the registered list is checked, and no inference is done nor the operator actually executed, there is no way to check the implementation of the operator in this case. Moreover, the TFLite model already has the shape information of each layer, and the shape is not inferred again during the conversion. The information regarding operator implementation and network shape is checked only when calibrator.py is working. So, theoretically, on-board operation will have no problem as long as the IPU_SDK can convert the model into an Offline model.
Q: In what kind of scenario is it recommended to set the quantization of input_config to FALSE?
A: It is generally recommended to set the quantization of input_config to FALSE when the input data is non-image type, for example RAWDATA_S16_NHWC.
Q: What does the result generated by cmodel_float.sim signify?
A: The cmodel_float.sim model contains quantization information, but the intermediate file can be left unused.
Q: Is there any limitation regarding the dimension output by Concatenation?
A: When using Concatenation, please pay attention to the dimension output by the Concatenation.
For example, suppose the dimension after reshape is 1x150x40 at input, the dimension of 1x600x40 should be 1x750x40 at output. If in this case the output dimension is 750x40, minmax error will happen during the quantization process.
Q: Can I use ARGB image format on 3-dimensional model input?
A: Image in ARGB format cannot be used when the model input is 3-dimensional.
For example, if the input format is NV12, the training format cannot be ARGB. In this case, only RGB and BGR can be used as the training format.
Q: Is there any restriction concerning the version of the operator used for Onnx model conversion?
A: If any problem happens during the Onnx model conversion, check the version of the op, since the structure of the operator can be different depending on the version used.
Please visit the link https://github.com/onnx/onnx/blob/master/docs/Operators.md to see the difference among different versions. If any unsupported op version is intended, please let us know.
Q: There is an error with the pb file used for conversion of backbone network by TensorFlow official model zoo. What is the problem?
A: If pb file is used for conversion of backbone network by TensorFlow official model zoo, the TFLite_Detection_PostProcess node should be exported.
Q: Where can I check the input/output tensor name of the model actually used during conversion?
A: You can use Newtron to check the actual input/output tensor name of the model used during conversion. See the following diagram for example.
Q: How to use the calibrator's post-processing method?
A: Calibration against ssd_mobilenet_v1_concat.tflite alone is possible; please set -c to Unknown.
However, you cannot do calibration against ssd_mobilenet_v1_postprocess.tflite, since the input is not an image.
Calibration is possible in cases where the input is an image, for example backbone network. But the optional parameter should be set depending on its type. If you are not sure the type is classification/detection, set -c to Unknown. To set -c to Detection, you should use the postprocess, i.e. the concat_net provided by SigmaStar, to concatenate the network. And even if -c is set to Unknown, you can still use the simulator to test Top1 when the calibration is done.
-c Classification: The network has only one output. The tool will classify the output results automatically by score and list the top 5.
-c Detection: Can be used only when concat_net is used to concatenate the postprocess network.
-c Unknown: Can be used in all networks. This will output the data of each output Tensor.
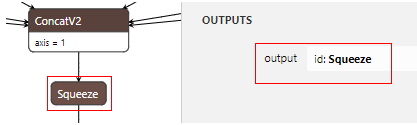
Q: Should the output of --output_arrays be consistent with the output in the input_config.ini file?
A: The following error message will appear as a convert tool error if the output of --output_arrays is not consistent with the output in the input_config.ini file.
output arrays is not correct in op_config.ini,pls check!!!!
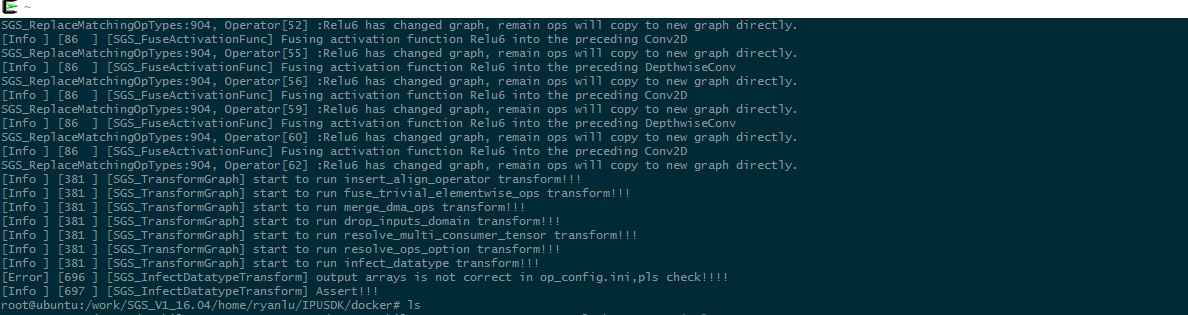
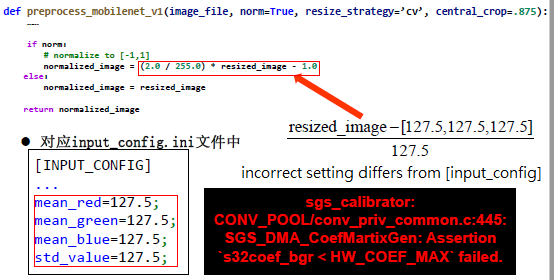
The mean and standard values shown in input_config.ini are normalized data used during network training.
The convert tool will have problem if these values are inconsistent. Besides, the normalization value in the preprocessing method should be identical with the value in input_config. An error will be reported if the input min and std values gotten from statistics after the calibration are different from those in input_config.ini. The min and std statistical values are related to the image preprocessing method. As such, the image preprocessing method should have the same settings as the min/std values in input_config.
Q: Is there anything I should do when switching between models having different versions?
A: When switching between models having different versions, be sure to re-source cfg_env.sh so that the bin file will direct to the correct version when you do global export.
Q: Does the number of images used in calibration have anything to do with the performance?
A: The more images you use for calibration, the closer the performance will be to the performance of a float model. So you can check which one is closer to the float model by the number of images used.
Q: Is there any usage restriction befor and after the mean value?
A: There is a usage restriction before and after the mean value. The dimensions should be consistent at input and output sides, to avoid problem during conversion.
Q: What should I pay attention to when using GlobalAveragePooling2D?
A: When using GlobalAveragePooling2D, the Mean operator will be transposed.
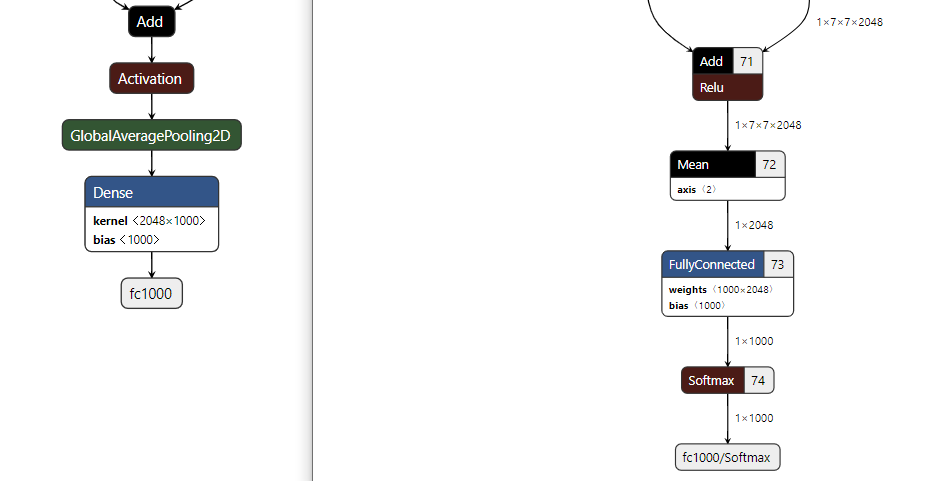
Our SDK operator supports AveragePooling2D, in which flatten will be removed in the process of h5→tflite.
Error which occurred during calibration: Assertion s32coef_bgr[i] < HW_COEF_MAX failed.
The batch_size in the Onnx model converted by Pythorch cannot be a string; otherwise, an error will happen during calibration.
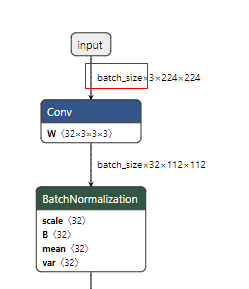
The IPU SDK does not support multi-batch. The configuration depicted in red box in the figure below should be removed when converting from PyTorch to Onnx.

Q: Does the segmentation in Onnx support maxunpool operator?
A: The segmentation in Onnx does not support maxunpool operator.
Q: What is the input format when the training model is not in NHWC format?
A: If the dimension of the training model is not in NHWC format, the input format in input_config.ini should be set to RAWDATA_S16_NHWC.
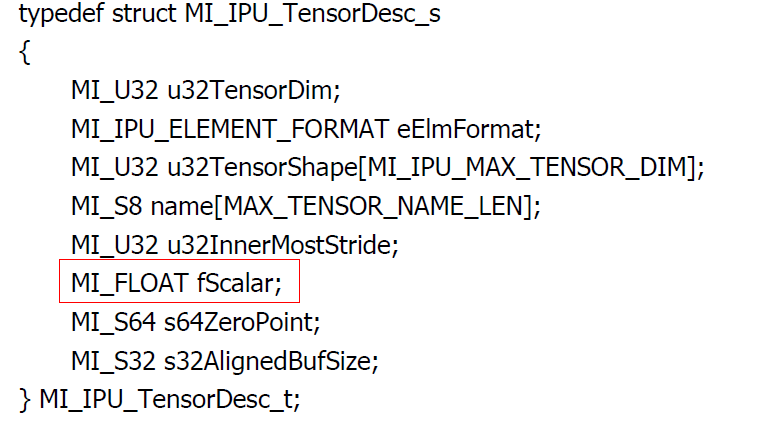
Note: When RAWDATA_S16_NHWC is used, the input data running on the board should be divided by scale and converted to S16 data, with the last dimension of the data aligned to 8, before it is filled in the input tensor.
The value of scale is the fScalar in MI_IPU_TensorDesc_s structure.
Q: Is image input in batch size supported?
A: The converted model does not support image input in batch size. Only one single image is allowed for each input, so the N will be 1 in all events.
For training models, however, you can select and input multiple images. The batch size in this case refers to the number of samples (frames) selected for input.
Q: What is referred to by input_array_depth?
A: The input_array_depth set forth in the manual refers to the C in NHWC.

Q: How to convert model using TensorFlow higher than 2.0?
A: If the version of the TensorFlow is higher than 2.0, please use TOCO to convert the model. For the method of conversion, visit https://www.tensorflow.org/lite/convert
Please use TensorFlow version 1.14.0 environment to check whether the converted TFLite will work normally, since all our operations are based on version 1.14.0.
Q: Why can't I use the official ssd_mobilenet_v1_fpn for SigmaStar postprocessing method?
A: The official ssd_mobilenet_v1_fpn cannot perform the SigmaStar postprocessing method, because the NMS bbox exceeds the limitation.

To solve this, implement the post-processing method at MI side, that is, have ARM execute the post-processing to relieve the 24567-BBox limitation, or re-train the model so that the number of output BBoxes will not exceed the limitation.
I received the message "Custom/op_custom_ssd_nms_float.c: sisi [0] unsupported num" after simulating the detection of float.sim. What does it mean?
**xxxxxxxxxxxxxx External Preprocess Data xxxxxxxxxxxxxx**
**Custom/op_custom_ssd_nms_float.c: sisi [0] unsupported num**
**detection_boxes Tensor:**
**{**
**tensor dim:3,shap:[1 100 4 ]**
**tensor data:**
A: "Custom/op_custom_ssd_nms_float.c: sisi [0] unsupported num" means nothing is detected.
Q: IPU SDK will do prune/sparse optimization during conversion. If I fine-tuned the prune/sparse model previously, will the acceleration effect still remain?
A: Yes, as long as the accuracy is improved, the output model will be optimized.
Q: Is it possible to set the std value of input_config.ini individually as the mean value?
A: The answer is positive.

Q: Why is the number of channels in NHWC_S16_rawdata changed from 1 to 3?
A: Due to hardware limitation, the convolution does not support operation with C = 1.
Q: How to load encrypted model on the board?
A: A model is encrypted by encrypting the img file. After that, you should compile the decryption functions MI_IPU_GetOfflineModeStaticInfo and MI_IPU_CreateCHN. These two functions have function pointer interface, through which you can call the decryption functions just compiled.
Q: The floating model has been successfully converted, but a message "eltwise do not support" returned at the same time. Does this message imply any problem?
A: Please ignore this message if the model has been successfully converted.
Q: If the network layer of a quantization model requires that the quantization be converted to 16-bit when the calculation amount exceeds 8-bit, is there any means to find out which network layer exceeds the 8-bit calculation amount?
A: You can dump the node information using calibrator_custom to verify this.

Q: If the model input shape is RGB (224,224,3) with 3-channel and the training model is in RGB format with gray-scale image input, can I apply the method of operation mentioned in Gray Scale Model Conversion section on PC/board? In other words, when running on PC, the image on the board should be in YUV format. Is that right?
A: There is no guarantee that the accuracy would be problem-free in the case where the model to be converted is in RGB (224,224,3) format with 3 channels while the training model is gray scale RGB format.
Q: Will the following errors generated in the course of concat_net affect the model conversion?
[Error] [1667] [SGS_IsConstTensor] Invalid parameters. [Error] [1667] [SGS_IsConstTensor] Invalid parameters. [Error] [1667] [SGS_IsConstTensor] Invalid parameters. [Error] [1667] [SGS_IsConstTensor] Invalid parameters. Concat all model to XXXXXXXXXXXXXXXX.sim done
A: These error messages are normal log inputs. The concatenation should be okay so long as you have properly input the concatenatd model.
Q: The calibration of Yolov3 model failed and the following error occurred. Why?
sgs_calibrator: Lut/lut_cmodel_float.c:494: SGS_Exp_CmodelFloatFinalizeOpParam: Assertion `fabs(output_tensor_scale-scale*exp(pstTargetOpt->stLutExtraStatic.fHisMax)) < FLT_EPSILON' failed. Aborted (core dumped)
A: The main problem here is that the user did not pay attention to the memory space available when using cloud server. If the memory space left is not enough, unexpected errors will occur when you use multi-process to run calibration.
To eliminate this problem, you can use single process to run the calibration instead.
Q: Post-processing using Yolov3_6 did not work normally, why?
A: Yolov3_6 is no longer supported by the new IPU SDK. Please note that post-porcessing model within the SigmaStar IPU SDK supports Yolov3_7 only.
Q: Can I set the value of nms_score_threshold in the post-processing model to a very small number, for example 0.005? Is it necessary to set the value within the range (0.5-0.7) during Coco data verification?
A: This requires further verification.
Q: Is the compile error which occurs during output of resize_bilinear solved?
A: The problem of compile error which occurs during output of resize_bilinear has been fixed and verified on Pudding platform. Please upgrade your IPU SDK to version 1.1.4 or above.
Q: Can the detection network use VOC2007 to test SigmaStar offline network model to confirm the model conversion effect?
A: Currently the IPU SDK only supports use of COCO dataset to verify test accuracy.
For example, you can verify the dataset of the detection network (with COCO dataset support) as follows:
python3 ~/SGS_IPU_SDK/Scripts/calibrator/simulator.py \ -i ~/SGS_Models/resource/detection/coco2017_val_set100 \ -m ~/SGS_Models/tensorflow/ssd_mobilenet_v1/ssd_mobilenet_v1_float.sim \ -l ~/SGS_Models/resource/detection/coco2017_val_set100.json \ -c Detection \ -t Float \ -n ssd_mobilenet_v1 \ --num_process 10
As for how to count the mAP of the output results, you have to refer to the statistics script of the original Caffe model. Since the model and dataset used are different case by case, the IPU toolchain only provides a method to count the mAP and IOU based on the network output results of our post-processing. There is no general tool for this purpose.
Note that the VOC2007 test set should be used together with an open-source tool.
Convert the VOC2007 labels from .xml into .json, and then convert the IOU results into mAP. If any conversion problem happens at this junction, you should do further verification.
Q: Why does the size of the offline model get much bigger after applying the ArgMax operator?
A: When the offline model records instructions of the ArgMax's input [1,464,464,24] and output [1,464,464,1], the innermost dimension 1 of the output [1,464,464,1] will be used as a for loop in unit of 8, according to our alignment strategy. This accounts for the larger instruction set and the lower model operation efficiency.
So, if the ArgMax output dimension can be modified to [1,464,464], the operation efficiency will be increased by 8 times and the size of the offline model will get smaller too. As an alternative, you can consider moving the ArgMax calculation to the code outside the model to eliminate this problem.
Below are some extended discussions on how to modify the output dimension in question.
If we modify directly on Onnx model the output to [1,464,464], will the Convert Tool convert it back to [1,464,464,1]?
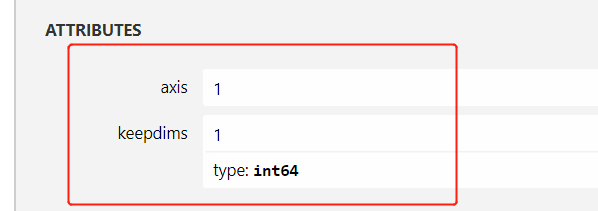
Since the attribute keepdims of ArgMax operator is still true, the IPU SDK toolchain will deem it necessary to keep the inner dimension. So, to prevent the output dimension from being reverted to the original setting, you should change keepdims of ArgMax operator to false, and modify line 354 of the script
IPU_SDK/Scripts/ConvertTool/mace/python/tools/onnx/SGSModel_transform_onnx.py from if len(output_shape[0].dims) == 4:#nchw ->nhwc to if len(inputShape) == 4:#nchw ->nhwc
and then reconvert the float.sim model.
Q: Why is the detection rate of detection related tasks much lower as compared to the PC (PyTorch) results, after the model is converted into a fixed model? More images have been used to do calibration statistics, to see if any min/max value has been set by the user to the layer from outside the model to reduce the difference. Does the IPU provide such function?
A: Please refer to "Rule for Importing the Quantization Parameter" section of the Manual.
First, ascertain whether the loss of accuracy happens in the backbone network or in the post-processing network. If the portion suffering from loss of accuracy is the backbone network, the quantization tool provided by our calibrator can help retrieve the accuracy by using hybrid quantization to achieve a balance between speed and accuracy. So it is not necessary in this case to manually input the min/max value of the layer.
The min/max value of each layer is user-defined. However, how much error can be reduced by manually inserting the min/max value of the layer, and whether it can achieve a satisfactory result, will require a try.
Q: There are two parameters in input_config: training_input_formats and input_formats. input_formats represents the format of the image on the chip or simulator after being converted into SIM file (which is RGBA in this case). However, when we change input_formats to RGBA, and view the converted model using Netron, the input size is still 3-channel. Besides, we cannot input image with RGBA format (an error message showing dimension mismatch will appear) when trying to run the converted model by the simulator. How should this parameter be used?
A: For the conversion of input_format to training_format, operators will be generated in the model only when the model is converted to a fixed-point/offline model.
Hence, to run simulation on PC, please use the same image format as training_input_formats.
To run simulation on development board, you can use image format same as input_formats.
Q: For post-processing, can I adjust the backbone to have part of the model connected to and output after post-processing and part of the model output directly?
A: Yes, this feature is supported by IPU SDK v1.1.3 (Pudding) / vQ_0.5 (Tiramisu) and above.
IPU on EVB Board¶
Q: When input_formats is YUV_NV12 or GRAY, how to set MI_SYS_PixelFormat_e?
A: Please set MI_SYS_PixelFormat_e as E_MI_SYSPIXEL_FRAME_YUV_SEMIPLANAR_420.
Q: How to get the memory configuration used by the IPU by cat /proc/mi_modules/mi_ipu/mi_ipu0?
A: The memory used by ipu_firmware is located at mma_heap_ipu, and the others located at mma_heap_name0.
Q: Why is the offline model generated on EVB board different from the one generated on PC when the same bin of rawdump is used?
A: Check if the parameter dequantization is set as false. If false, the output will use S16 bit format, instead of being divided by the scale ratio to get the float type value, thereby causing the result to be different from the result obtained by the simulator.
Q: Why is the memory content accessed incorrect?
A: Because IPU_invoke() will allow the IPU hardware to access the memory directly, if the cache is not flushed, the contents of the access can be inaccurate, thereby causing the IPU to hang.**
To avoid this issue, be sure to flush the cache after completing the memcpy operation.
Q: How to ensure that two models with functions different in fps time can be executed at the same time without any problem?
A: MI IPU guarantees that users can call MI_IPU_Invoke in parallel. However, since the IPU is single core, the IPU will do serial processing internally. As for the arrangement of the algorithms to be executed in parallel, users can have their own design.
Q: There will be invalid/flush cache operation at the bottom of MI_SYS to avoid cache-memory inconsistency, when using channel pipeline, right?
A: For input tensor, the MI IPU will not carry out any flush cache operation. Users should guarantee by themselves that MI IPU will handle the cache problem (for example, when CPU accesses the input tensor, invok MI flush function before acessing the output tensor).
Q: Is it true the DMA inside the IPU does not allow API operations?
A: No API operation is permitted in the internal DMA within the IPU, since operators such as Gather, Unpack, Pack, Concat, Reshape, Slice, Tile, Tanspose, Pad and Split would use the internal DMA of the IPU. To be more precise, each operator uses the internal DMA operation provided by the IPU.
Q: How to operate the IPU clock?
A:
Check the current IPU clock rate:
cat /sys/dla/clk_rate
Echo NUM > /sys/dla/clk_rate:
echo 1000 > /sys/dla/clk_rate
IPU power switch command:
echo 1 > /sys/dla/power to open the power, and echo 0 > /sys/dla/power to close the power.
You can also enclose the Linux command in system(" ") of the code.
For example, system("echo time_statistic > /proc/mi_modules/mi_ipu/mi_ipu0 ").
Q: Can I set the IPU clock to 1000MHz, or even 1200MHz?
A: IPU clock is normally set to 800MHz or 900MHz. Setting it to 1000MHz or 1200MHz can lead to the risk of instability of the hardware system.
Q: How to check the IPU SDK version currently supported by the FW SDK?
A: To check the IPU SDK version currently supported by the FW SDK, you can check the checksum of /config/dla/ipu_firmware.bin or project/board/i6e/dla_file/ipu_firmware.bin, using the following command
md5sum /config/dla/ipu_firmware.bin
and compare it with the ipu_frimware.bin in the IPU SDK to see if they are consistent.
Q: Do you have any documentation for the dla_xxx app?
A: Some descriptions can be found from the readme.txt file in the directory mi_demo/alderaan/dla_xxxx. For those apps without readme.txt file, a prompt will be provided in the process of operation.
Q: Should the version of the DLA SDK be aligned with the version of the FW SDK?
A: Yes, the model itself needs to be re-converted on the new version and aligned with the version of ipu_frimware.bin/FW SDK. Besides, the program of prg_dla_xxx also needs to be re-compiled, instead of being run directly.
Q: How to use dla_classify app?
A: The dla_classify output uses softmax to obtain TOP5.
Order 0 represents the top-1 class probability.

The top-1 class probability is not the same thing as top-1 accuracy.
A picture will have a probability value of 1000 classes after process, whereas the percentage of accuracy is inferred after the processing of 50,000 pictures.
Top-1 accuracy is calculated by processing N pictures, to calculate the percentage of accuracy in the Top-1 class of these pictures.
Note that the output will not be shown in percentage if softmax is not used.
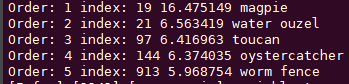
In the example above, the model did not apply softmax, so the output is shown as score, rather than a percentage probability.
As a rule, you can use softmax if the score can be converted into probability.
For more information, go to: https://zh.wikipedia.org/wiki/Softmax%E5%87%BD%E6%95%B0
Q: What is the method of comparison of network structure accuracy?
A: Since each network structure is different, we cannot make a side-by-side comparison straightforwardly. As a simpler method of comparison, you can use the same picture to compare the output results of float and fixed networks. If the output results of the two networks are similar, it means the quantization performed has no particularly serious errors. A more formal way of comparison is to use statistical method to compare the results of the verification dataset. For network trained by imagenet, the verification dataset is composed of 50,000 images.
Q: Is there a matlab interface to verify the accuracy of on-board execution?
A: We do not provide a matlab interface. However, you can modify our demo process using the C interface of the matlab. For more details, please visit the link below:
https://www.mathworks.com/help/matlab/matlab_external/reading-a-mat-file-in-cc.html
Q: What is the version of the open-cv in the SDK?
A: The open-cv in the SDK is the complete build 4.1.0 version.
Q: What is the model/verification dataset lable used by dla_detect?
A: caffe_yolo_v2 is the model of voc dataset. Note that the label is different from that used by mscoco.
Q: Why is the error "fstat: Value too large for defined data typ" generated when DLA (IPU) is run on the NFS mounted on the board?
For example, get variable size from memory__ fstat: Value too large for defined data type ReleaseAllBuffer count =0
A: For Arm+Linux embedded systems, the kernel does not support cifs file system by default. So when compiling the kernel, cifs file system support is required; otherwise, the option "nounix, noserverino" should be added. It is found that this problem no longer occurs after the "nounix, noserverino" option is added before mounting. So the complete mount command may be as follows:
#mount -t cifs -o username=Everyone,password=xxx ,nounix,noserverino //192.168.88.77/nfs /mnt
Q: What is the limitation regarding invoking model by running Python on the board?
A: Let's take image model input as an example.
model.set_input(0, image) can only use uint8, with img = np.round(img).astype('uint8'). That is, you need to convert the datatype of the image to uint8 before input.
Q: The result of dla_classify is different from the result obtained by Python lib on the board but identical with the result gotten from the simulator. Why?
A: This is due to a difference in the implementation of the round function. It is rounded in cpp, but not in Python. To make them consistent, follow the steps below:
-
Modify the Python function of the PC simulator:
img = cv2.imread("ILSVRC2012_test_00000002.bmp")#[:,:,::-1] img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) new_size = 224 resized_im = cv2.resize(img_float, (new_size, new_size), interpolation = cv2.INTER_LINEAR) image = resized_im image = np.expand_dims(image, axis=0) model.set_input(0, image) -
Have the Python on the board apply the same pre-processing, to make the results of the PC and the Python on the board consistent.
Q: How to dump the network model information?
A: By using parse_net/parse_img, you can dump the network model information.
For example,
to get variable tensors info:
SGS_IPU_SDK/bin/parse_img caffe_yolo_v3_darknet_fixed.sim_sgsimg.img | grep Variable SGS_IPU_SDK/bin/parse_net caffe_yolo_v3_darknet_fixed.sim | grep Variable
Q: Since yolov3 will generate two outputs in backbone, is it possible to decide whether 13x13 or 26x26 is the front dimension in the concatenated network for BBox decoding?
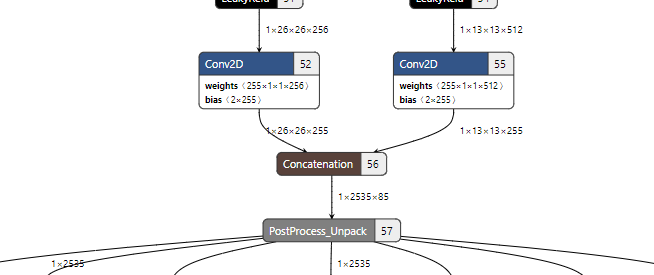
A: The most accurate way is to expand the concatenated network, thereupon you will see two inputs on the right. Then arrange them in order of up and down to see which one is the front dimension.
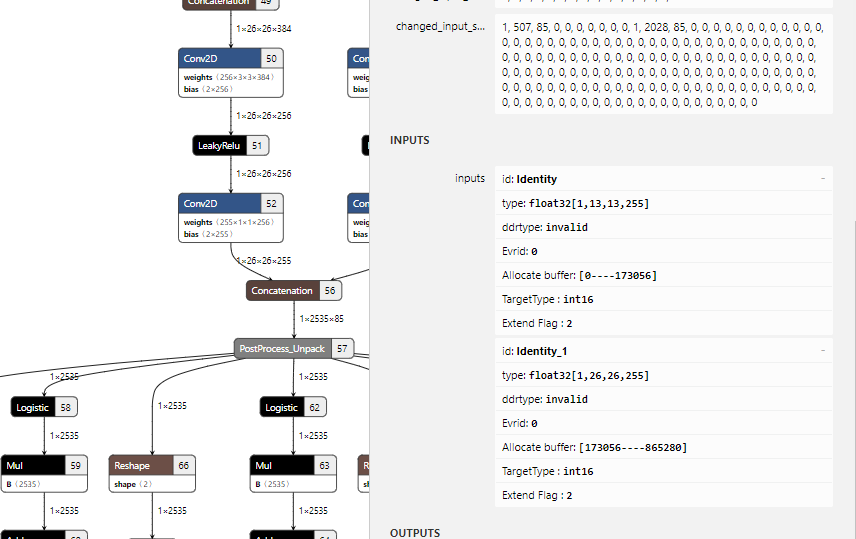
As illustrated above, after the concatenation, 13x13 is ranked first for BBox decoding.
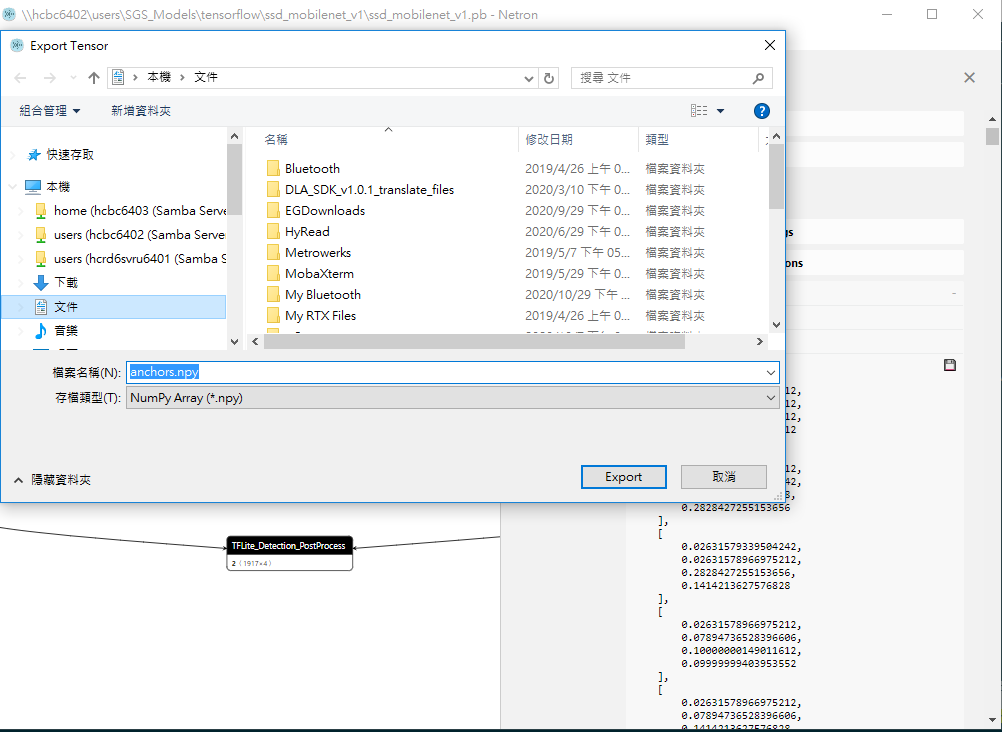
Q: How to save the anchor parameters (*.npy) of the detection models?
A: Use Netron to open the pb model in tensorflow/ssd_mobilenet_v1 of the SGS_Model, and click to open the last node of the model. You will see an anchor tensor on the right. Use Netron directly to save the npy. (Note: To save npy, you need to export the node with TFLite_Detection_PostProcess.)
Q: How to dump the kernel errors of the IPU SDK core?
A: Run the following command in docker:
echo core > /proc/sys/kernel/core_pattern ulimit -c unlimited
Then re-run the model conversion. A core file will be generated when an error occurs. Then run
gdb -ex "info proc mapping" --batch /path/to/SGS_IPU_SDK/bin/sgs_calibrator /path/to/core gdb -ex bt --batch /path/to/SGS_IPU_SDK/bin/sgs_calibrator /path/to/core
Q: Can the semantic segmentation method be used in the SigmaStar SDK?
A: Use Unknown when the tool runs the calibrator and set -c to Unknown when using the simulator. After the operation is done, the data will be saved in a txt file under the path ./log/output/. You can compile a separate post-processing function to process these data. How the output file will be processed has nothing to do with the SigmaStar SDK. It is the --n parameter of the calibrator used for the image processing carried out by the customer implementing the semantic segmentation method that actually influences the calibration. The --save_input uses simulator in ./log/xxx.jpg.data. The --save_input in ./log/output/xxx.jpg can output data of an image for classification based on that image.

Q: Can non-NHWC input model be converted into an offline model?
A: Non-NHWC input model cannot be converted into an offline model. You need to re-train a model with gray-scale image input.
Note that if FullyConnected operator is used, 2-dimension input is not permitted. To run this operator, you can either use models with 4-dimension input, or add a convolution to the first layer to allow the following layers to use FullyConnected operator.
The RAWDATA_S16_NHWC format does not use image data and has nothing to do with mean/std. It will not do mean and std operations in the model. An example of RAWDATA_S16_NHWC is located in alkaid/sdk/verify/mi_demo/alderaan/dla_rfcn, in which the model is segmented with the last two model segments having input in RAWDATA_S16_NHWC format.
Q: Where to find the API for TensorFlow conversion?
A: https://tensorflow.google.cn/lite/convert/index
Using this convert API can avoid the problem of some tensor names having multiple semicolons.

Q: At present, the TensorFlow core uses tf1.14 version. Is there any restrictions on the version supported?
A: In TensorFlow, *.pb and keras *.h5 are limited to models trained by tf1.14; besides, the TensorFlow *.pb needs to be exported to frozen inference graph for TFLite. Hence, we recommend that you convert *.pb or *.h5 to *.tflite to avoid any issue arising from model training version support. Basically TFLite operators up to tf2.0 are supported. We will continue to update the version supported when new operators are added.
Q: For pre-processing, if normalization is not performed, will there be any problems if I set mean RGB to 0 and std to 1?
A: The use of pre-processing is primarily to ensure that the training model and the model for conversion and quantization use the same image normalization method, so that the conversion and quantization model is consistent with the training model. If you are sure that the normalization process is not performed right from the start of the model training, setting mean RGB to 0 and std to 1 will not be a problem.
Q: What is the purpose of compiling the pre-processing file during calibration?
A: When doing calibration, you need to configure the pre-processing file, because an applicable pre-processing method is required to resize or normalize the image data of the training set when the model is converted to a fixed-point or offline model. As such, when compiling the pre-processing file, make sure that it is consistent with the pre-processing method used to train the model.**
For example, Keras has its own pre-processing library and OpenCV likewise has its own pre-processing library. Even if the same normalization is performed, there is still a certain degree of difference between them in the processing of image data. So, the pre-processing files respectively used by the training model and the conversion and quantization model should have the same configuration, including the public library used; otherwise, some loss of accuracy may occur after the model is quantized.
Q: What is the method of accuracy calculation used by the simulator?
A: After simulation, the simulator will generate log/output files. Among them, the output file contains prediction type and accuracy corresponding to images of different test sets. Since it is necessary to output the type, the model should identify different types using the output of the softmax operator, so that you can calculate the correct accuracy based on the ground truth label. If the output is merely the output of activation function 1x1, and the type is judged by threshold only, you will not be able to directly calculate the accuracy on the simulator. Instead, you have to parse the output value in each log/output file to calculate the accuracy.
Q: An error "fail to get ipu mma heap name when enable miu protection" occurs when I run the DLA/IPU process on the board. What does it mean?
A: If this error occurs, it means the config_file is not configured yet.

Q: Theoretically, when gray-scale image is used as the input format, the model should automatically expand to 3-channel during conversion when the configuration C=1 is set. But why is it required to input image in NV12 format when offline model is run on the board?
A: This is a special case. When YUV is used as the input, only Y channel will work, and UV will be channel 0.
Q: It seems that, for some specific model, the segmentation fault: s32AlignedBufSize and model input data size restriction will appear when the user accesses the output tensor buffer or calls the malloc(). Is that right?
A: If the input data size of the input model exceeds s32AlignedBufSize, a malloc segmentation fault will occur.
For example, the memory allocation size of input tensor mma is dependent on s32AlignedBufSize.
So if gray-scale is used as the input format, the information dumped by using parse_img from the offline model converted by the training format will be as follows:
104 | |--> SubGraph[0]: aInputFormat[1] = [ GRAY ]. 105 | |--> SubGraph[0]: aTrainingInputFormat[1] = [ RGB ].
In the offline model, input tensor[0] with element format = MI_IPU_FORMAT_NV12 is used.
For an image with width and height = 64x64, the input data size is limited to 3/2x64x64 = 6144. So if data of the size 3x64x64 is input, it will exceed the memory space allocated by s32AlignedBufSize.
Some models may exceed the input data size restriction imposed by s32AlignedBufSize without encountering the malloc segmentation fault. This is because the memory space is allocated with 4k alignment, and so if the size is smaller than 4k, a 4k buffer size will still be allocated.
Note:
-
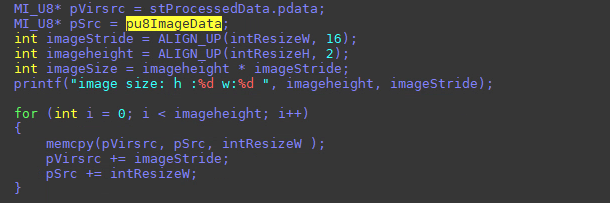
Use OpenCV to read image with yuv_nv12 format.
-
Read raw data bin file, and then save the raw data to the input tensor after alignment. When input_formats is set to YUV_NV12 or GRAY, the alignment rule is: stride = alignment_up(width,16), where the height needs to be aligned to 2.
See the following for example:
Power Measurement¶
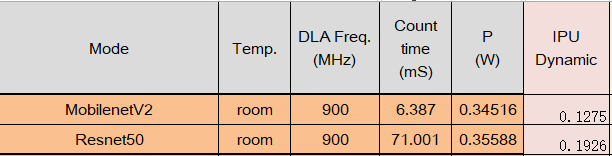
Q: What is the IPU power consumption reference data for Pudding?
A: Please see the table below for details.
Open Source Library Support¶
Q: Is OpenBlas supported?
A: ARM CPU supports OpenBlas, whereas IPU does not. The OpenBlas is an open-source implementation. You can use the toolchain provided by SigmaStar to build your own. You can also use the lib already built, which is available from: https://archlinuxarm.org/packages/armv7h/openblas
Q: Is hardware accelerator implemented in OpenCV?
A: OpenCV does not use hardware accelerator; it is simply operated with the CPU.
Q: Does the current SDK library support opencv-cntrib compilation?
A: Currently, ARM toolchain is available for user compilation, if deemed necessary.
Q: The fps achieved by ssd_mobilenet_v1 is 50fps, and the fps achieved by ssd_mobilenet_v2 is 38fps approximately, according to the previous record. Why is v2 slower to execute than v1 when theoretically v2 is supposed to have higher accuracy and efficiency than v1?
A: It seems that mobilenetv2 uses an additional 1*1 convolution to reduce the input/output channel and size required. In theory, the faster speed should be applied to PC. However, in the benchmark on our Pudding platform, mobilenet_v2 does execute slower than mobilenet_v1, due to convolution efficiency. For Pudding hardware design, the efficiency will be rather high if the input and output of the convolution use a very large C value and smaller h, w values. Since part of the convolution in mobilenet_v2 comprises a smaller C value, and the op in it is greater than that of mobilenet_v1, the actual performance on Pudding platform is less than expected. These will be ameliorated in the Tiramisu platform. Some test data from Tiramisu have demonstrated mobilenet_v2 to be more efficient than mobilenet_v1.
Q: How to deal with the time-consuming issue inside the network?
A: You can modify the process by executing while(1); before MI_IPU_DestroyCHN and MI_IPU_DestroyDevice to hold the process.
Once the process is run, use Telnet to create a new terminal. Then use the following command to check the time consumed within the network:
echo time_statistic > /proc/mi_modules/mi_ipu/mi_ipu0
An example result is as shown below:
printk in _MI_SYS_IMPL_Common_WriteProc [0] Decoder0 Offline mode : start: 3947194844 - 4023751804 duration: 76556960 opName:CONV_2D [1] Decoder0 invoke by cpu: start: 4023815546 - 4028075778 duration: 4260232 opName:RESHAPE [2] Decoder0 Offline mode : start: 4028086459 - 4032743622 duration: 4657163 opName:TRANSPOSE [3] Decoder0 invoke by cpu: start: 4032758722 - 4033198728 duration: 440006 opName:CONCATENATION [4] Decoder0 Offline mode : start: 4033209982 - 4043332592 duration: 10122610 opName:CONV_2D [5] Decoder0 invoke by cpu: start: 4043344284 - 4043705314 duration: 361030 opName:RESHAPE [6] Decoder0 Offline mode : start: 4043716080 - 4043903312 duration: 187232 opName:CUSTOM [7] Decoder0 invoke by cpu: start: 4043938642 - 4045046898 duration: 1108256 opName:CUSTOM Total execute time : 3947176362 - 4045057222 duration: 97880860 IPU_execute_time : 91523965(93.50%), CPU_execute_time: 6169524(6.6921469758919409694%), IPU<=>CPU: 187371(0.-4294967277%). cat /sys/dla/clk_rate
By dividing the result of the above duration by the IPU frequency, you will get the time required to complete network inference for each run (unit: s). The result will be correct if the fps gotten from the verification is similar to the fps gotten from the previous test.
Here is the method for testing network efficiency.
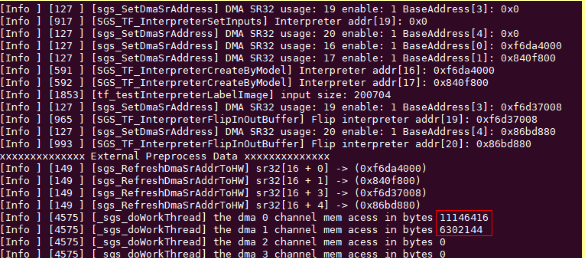
The bandwidth occupied by IPU is related to the network model used. Please refer to the SGS_Models_information table.

The bandwidth of one frame can be obtained by running fixed model using simulator.py. By adding up the values shown in red box in the image above, you will get a rough bandwidth (in byte) occupied by one frame.
Q: How to view the output tensor memory layout?
A: After the Fixed and Offline models are invoked, the final dimension of the output data will be aligned upwards to 8.
For example, you can use simulator.py to process one frame on fixed network, with -c set to Unknown. After the processing is done, you can check the shape data from screen log and ./log/output/unknown_xxx.txt.
**Squeezing the Tensor"
Tensor Dim: 3, Original Shape: [1 1917 4], Alignment Shape: [1 1917 8]
Due to the principle of writing data in hardware, no matter what PC is used, the tensor-squeezing phenomenon will occur whether in simulation or in actual operation on the board.
Note: You can use simulator to dump the output tensors to verify if they correspond to the output tensors on the board. Make sure that your pre-processing method Scripts/calibrator/preprocess_method/ssd_mobilenet_v1.py is consistent with the pre-processing method on the board.
Q: What is the difference between Yolov3_6 and Yolv3_7?
A: The post-processing of Yolo is originally done with each output generated separately. With SigmaStar, we concatenate the three outputs to have the outputs generated at the same time. This practice, which applies to both Yolov3_6 and Yolv3_7, is different from the official version.
Yolov3_6 processes by class, at a slower speed, and is no longer under maintenance.
Yolov3_7 processes all frames at the same time, at a faster speed, and is currently recommended for use.
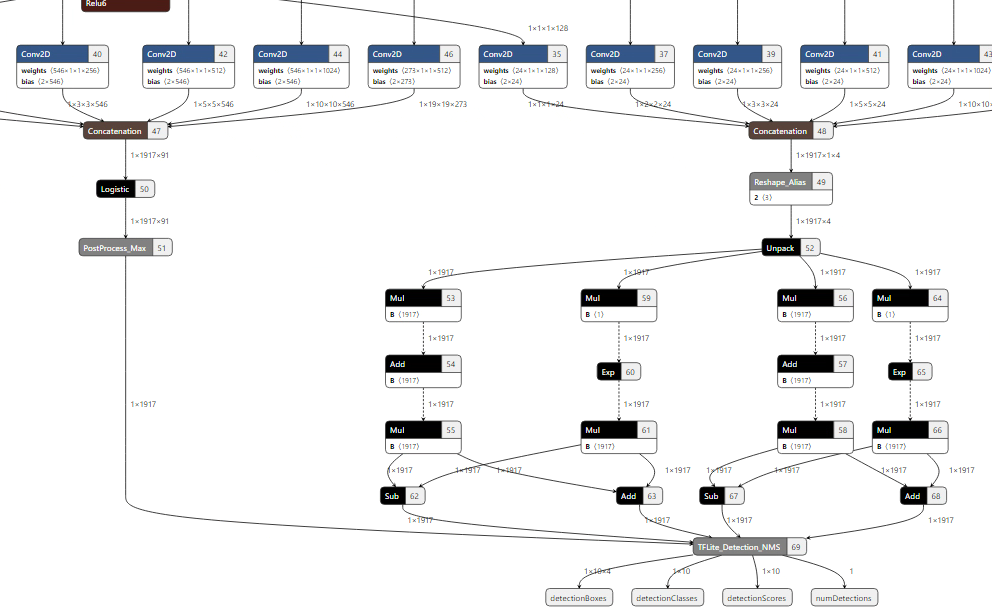
Q: How to use PostProcess_MAX?
A: When we calculate the conf. data of ssd-mobilenet on CPU, we don’t need any logistic function (yolov3_7 uses this function for conf. data).
The figure below shows the converted ssd-mobilenet offline model (with post-process).
Confidence is calculated by the ‘PostProcess_MAX’ operator. This operator only calculates (searches) the max conf. in classes and class index.
For example, before Postprocess_Max, there are similar softmax or logistic for conf. calculation.
Logistic function will be required if you have the logistic operator before ‘PostProcess_MAX’ operator in your post-process.
**Q: What does the layout of Yolov3 output data look like?
Is the output data layout below correct?
obj, c1, c2, c3, …, c89, c90, ig1, …, ig5,
where, obj means the objectness score, c1 means the class 1 confidence, and ig1 means data 1 (align up 8) should be ignored.**
A: There should be two output tensors. One is for the box (1x1917x4).
Example 1: Tensor Dim: 3, Original Shape: [1 1917 4], Alignment Shape: [1 1917 8]
In this example, the array should be [y,x,height,width,ig1,ig2,ig3,ig4], where ig1~ig4 refer to the ignored data for aligning up 8.
For scores (1x1917x91), there are 80 labels, 10 null labels, and 1 class for “no object detected”.
This is because it is trained on the COCO dataset, which means it can detect 90 possible types of objects, plus one class for “no object detected”.
Example 2: Tensor Dim: 3, Original Shape: [1 1917 91], Alignment Shape: [1 1917 96]
In this example, the array should be [c1,c2,c3,….,c90,c91,ig1,ig2,..,ig5], where ig1~ig6 refer to the ignored data for aligning up 8.
Q: Does the ‘PostProcess_Max’ operator calculate like this, (xm, m) = max(x1, x2, …, xn), where xm is the maximum value of x’s and m is the index of xm?
A: Yes, we select the maximum score, as the softmax does.
To get confidence in post-processing, calculate max value with c1,…, c90 above.
Q: When bufdepth is set to 0, can I use the front-stage divp as the output buffer to IPU channel if the input depth is 0 and no default buffer is used?
A: The input/output depth can both be set to 0. When 0, the user should provide his/her own buffer, for example, use the divp output buffer or a buffer allocated by MMA.
**Q: Is there any case in which it is absolutely necessary to allocate at least one buffer?
Between different IPU network models, is it required for input/output channel to allocate at least one buffer each, for back-stage input and front-end output, respectively?
In other words, the back-stage network channel should be equipped with a buffer, instead of being input directly like divp. Is that right?**
A: Since the front-stage is not a HW engine (DIVP) already equipped with a buffer, at least one buffer is required at system level.
If at least one buffer is required, is there any difference between allocating 2 buffers and allocating 3 buffers?
A: When the fps of the front-stage differs from the fps of the back-stage, bufdepth will provide an allowable time difference to avoid overlap. The larger the bufdepth, the more the memory will be consumed. This, however, will not impact the frame delay.
Q: Is there any difference between the use of MI_IPU_GetInputTensors/MI_IPU_GetOutputTensors and the use of MI_SYS_MMA_Alloc/MI_SYS_Mmap? Will bufdepth make a difference? If I set bufdepth to a non-zero, can I use the function directly to allocate the buffer depth?
A: MI_SYS_MMA_Alloc can get the buffer of physical continuous memory from MMA heap. Because the memory is continuous, the buffer gotten this way will have better efficiency than the buffer allocated by OS. To further enhance the efficiency, you can use MI_SYS_Mmap to map the physical addr to the virtual addr. This is because virtual address, if used instead of physical address, will use cache and will thereby further increase the efficiency of read operation. To ensure the data accessed is most up-to-date, remember to call MI_SYS_FlushInvCache. So, in general, it is recommended to use MI_SYS_MMA_Alloc in combination with MI_SYS_Mmap. When bufdepth is set to 0, you have to allocate the buffer by yourself using these two APIs. When bufdepth is not 0, the buffer will be allocated automatically by the bottom layer when you create a channel. Normally, when building a pipeline, the value of bufdepth will be set to allow the bottom layer to perform the allocation.
Q: How to feed data in YUV_NV12 input format to a model, in the following case?
Example:
# ./prog_dla_simulator -i yuv/0.jpg -m caffe_ssd_mobilenet_ v1_fixed.sim_sgsimg.img -c Detection --format RGB --ipu_firmware /config/dla/ipu _firmware.bin
Result: Segmentation fault
[ 8087.612230] [MI WRN ]: MI_SYS_IMPL_ConfigPrivateMMAPool[4943]: The current project supports MMU, and the private pot client [1512] Create IPU channel 0 [ 8088.889842] collect channel0's resource [ 8088.894233] au8SetProId[0]:0x71 [ 8088.897257] miu_number:0,start:0x25fe0000,end:0x26144000,flag:0 [ 8088.903142] --------shutdown IPU---------- [ 8089.016171] client [1512] disconnected, module:ipu [ 8089.024952] client [1512] disconnected, module:sys [ 8089.045243] ReleaseAllBuffer count =0 Segmentation fault
A: Please refer to the source code of prog_dla_simulator.
It is not necessary to use image in nv12 format. Please use jpeg or bmp image file of general test set to allow OpenCV to read. The prog_dla_simulator will convert the image into yuv_nv12 data, put it into the input tensor of the model, then invoke the IPU.
Q: Why the variable buffer size read out by the function MI_IPU_GetOfflineModeStaticInfo is 0?
A: A possible reason behind this is that, the binary file of prog_dla_xxx is not re-compiled under the new FW SDK, and because of this, the MI IPU API is not aligned. Please check if this is the cause in your case.
Useful Python Scripts¶
To quickly get the input/output tensor name:
##Note: can use below quickly to get input/output tensor name import tensorflow as tf gf = tf.GraphDef() m_file = open('frozen_inference_graph.pb','rb') gf.ParseFromString(m_file.read()) with open('somefile.txt', 'a') as the_file: for n in gf.node: the_file.write(n.name+'\n') file = open('somefile.txt','r') data = file.readlines() print ("\noutput name = ") print (data[len(data)-1]) print ("Input name = ") file.seek ( 0 ) print (file.readline())
To get the output tensors without pre-process method:
#raw_input.py# #Get outputs tensors without pre-process method# import os import struct import argparse import numpy as np import gc import calibrator_custom import time from functools import reduce def arg_parse(): parser = argparse.ArgumentParser(description='Simulator Tool') parser.add_argument('-i', '--image', type=str, required=True, help='Image / Directory containing images path.') parser.add_argument('-m', '--model', type=str, required=True, help='Offline Model path.') return parser.parse_args() def main(): args = arg_parse() image_path = args.image model_path = args.model if not os.path.exists(image_path): raise FileNotFoundError('No such {} rawdata image.'.format(image_path)) if os.path.isdir(image_path): raise FileNotFoundError('Rawdata image path {} is a dir.'.format(image_path)) if not os.path.exists(model_path): raise FileNotFoundError('No such model: {}'.format(model_path)) model = calibrator_custom.offline_simulator(model_path) in_details = model.get_input_details() print(in_details) out_details = model.get_output_details() print(out_details) img_size = reduce(lambda x, y: x * y, in_details[0]['shape']) with open(image_path, 'rb') as f: img_bytes = f.read(img_size) img_data = struct.unpack('B' * img_size, img_bytes) img_data = np.array(img_data).reshape(in_details[0]['shape']).astype(in_details[0]['dtype']) model.set_input(0, img_data) model.invoke() result_list = [] # eliminate alignment garbage in IPU100 for num, out_info in enumerate(out_details): result = model.get_output(num) print(result.shape) if result.shape[-1] != out_info['shape'][-1]: result = result[..., :out_info['shape'][-1]] # if 'quantization' in out_info: # result = result * out_info['quantization'][0] result_list.append(result) print(result_list) if __name__ == "__main__": main()
The voc2012_evaluation.py can use open-source "chainercv.evaluations.eval_detection_voc" to do mAP evaluation.
https://chainercv.readthedocs.io/en/stable/reference/evaluations.html
Please pay attention to the following during the evaluation:
-
In this example, the label can only read .txt file. Hence, the xml file of voc2007 should be converted to .txt format first.
-
The (ymin,xmin,ymax,xmax) coordinates gotten from the log file of the simulator are the coordinates of prediction BBoxes.
By passing the coordinates of prediction BBoxes, together with the (ymin,xmin,ymax,xmax) coordinates gotten from the ground truth BBoxes attached to the voc2007 .xml file,
by class of label to the API: schainercv.evaluations.eval_detection_voc(pred_bboxes, pred_labels, pred_scores, gt_bboxes, gt_labels, gt_difficults=None, iou_thresh=0.5, use_07_metric=False),
we can get the mAP evaluation of the VOC.
An example usage of the simulator is given below:
python3 ./../SGS_IPU_SDK_v1.1.3/Scripts/calibrator/simulator.py \ -i ./jpegs \ -m ./caffe_ssd_mobilenet_v1_fixed.sim_sgsimg.img \ -l ./../SGS_Models/resource/detection/voc_label.txt \ -c Detection \ -t Offline \ -n caffe_ssd_mobilenet_v1 \ --num_process 20
Here is an example log:
l/o/detection_caffe_ssd_mobilenet_v1_fixed.sim_sgsimg.img_2011_000002.jpg.txt buffers
1 {"image_id":2011, "category_id":3, "bbox":[142.798851,201.560355,77.982140,68.583569], "score": 0.934050},
2 {"image_id":2011, "category_id":3, "bbox":[354.248138,263.836108,44.994268,44.154712], "score": 0.144383},
3 {"image_id":2011, "category_id":3, "bbox":[392.347644,258.620458,47.342054,35.996901], "score": 0.051668},
4 {"image_id":2011, "category_id":3, "bbox":[237.007458,329.321491,50.254497,41.725200], "score": 0.049440},
5 {"image_id":2011, "category_id":3, "bbox":[399.658469,238.181351,48.560525,34.570398], "score": 0.048097},
6 {"image_id":2011, "category_id":3, "bbox":[431.635902,63.992014,20.149349,20.528264], "score": 0.046022},
7 {"image_id":2011, "category_id":3, "bbox":[434.786095,215.112129,50.521966,37.089067], "score": 0.044099},
8 {"image_id":2011, "category_id":3, "bbox":[448.248713,205.082033,41.101105,30.224023], "score": 0.042665},
9 {"image_id":2011, "category_id":3, "bbox":[445.514583,241.591583,34.087468,25.476444], "score": 0.036653},
10 {"image_id":2011, "category_id":3, "bbox":[446.198116,63.947435,23.685886,20.929467], "score": 0.032685},
Note:
-
In the og/output/detection_caffe_ssd_mobilenet_v1_fixed.sim_sgsimg.img_201100xxxx.txt generated after completion of the simulation, the string that follows the underscore in image_id column will be cut off directly. So if you don't want to modify the IPU SDK code, you should modify the "2011_000002" in the image name of the voc to "201100002" to avoid getting image names with the same suffix "2011".
To modify the image name in a batch, use the following command: find model -type f -name "_" -exec sh -c 'd=(dirname "1"); mv "1" "d/(basename "1" | tr -d _)"' sh {} \;
By so doing, there will be no problem with the file name comparison made by "voc2012_evaluation.py", and the count of "Total number of detected boxes:" shown after completion of "voc2012_evaluation.py" will be correct.
-
The .txt file generated after xml-to-txt conversion should be in a newline format, so that the correct format can be read in sequence when the get line command is executed:
Example: 2011_000007.xml.txt
1 6 76 106 240 328 2 7 64 198 23 26 3 15 32 264 40 113 4 15 30 253 18 58 5 15 6 241 10 38 6 15 4 263 34 87 7 7 340 159 35 22
import os import numpy as np from chainercv.evaluations.eval_detection_voc import eval_detection_voc import json class VOCConfiguration: def __init__(self): self.classes = [ "background", "aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "dining table", "dog", "horse", "motorbike", "person", "potted plant", "sheep", "sofa", "train", "tv monitor" ] self.segmentation_colors = 64 * np.array( [[0, 0, 0], [0, 0, 2], [0, 2, 0], [0, 2, 2], [2, 0, 0], [2, 0, 2], [2, 2, 0], [2, 2, 2], [0, 0, 1], [0, 0, 3], [0, 2, 1], [0, 2, 3], [2, 0, 1], [2, 0, 3], [2, 2, 1], [2, 2, 3], [0, 1, 0], [0, 1, 2], [0, 3, 0], [0, 3, 2], [2, 1, 0] ], dtype=np.uint8) self.voc2012segm_val_dir = '/work/workdir/dataset/VOC2012/' voc_cfg = VOCConfiguration() def compute_segm_iou(dt_arr, gt_arr, cls, ignore_edge=True): dt_arr = np.asarray(dt_arr) gt_arr = np.asarray(gt_arr) assert dt_arr.shape == gt_arr.shape, 'dt_arr.shape:{}; gt_arr.shape:{}'.format(dt_arr.shape, gt_arr.shape) pred_cls = (dt_arr == cls) gt_cls = (gt_arr == cls) sum_cls = pred_cls.astype(np.int32) + gt_cls.astype(np.int32) if ignore_edge: gt_ignore = (gt_arr == 255) pred_cls_roi = np.where(gt_ignore, False, pred_cls) union = np.sum(pred_cls_roi + gt_cls) else: union = np.sum(pred_cls + gt_cls) if union == 0: return 0 else: intersection = np.sum(sum_cls == 2) return 1.0 * intersection / union def get_val2012_gt(voc2012_val_sgs_root=None): """ Get groundtruth labels and bboxes for evaluation :param voc2012_val_sgs_root: root of the val2012 dataset :return: groundtruth labels and bboxes """ if voc2012_val_sgs_root is None: voc2012_val_sgs_root = os.path.join('/', 'work', 'workdir', 'dataset', 'VOC2012') val_txt = os.path.join(voc2012_val_sgs_root, 'ImageSets', 'Main', 'val.txt') gt_labels = dict() gt_bboxes = dict() image_ids = [] with open(val_txt, 'r') as fr1: for line1 in fr1.readlines(): name_body = line1.strip() label_file = os.path.join(voc2012_val_sgs_root, 'txt', name_body + '.xml.txt') labels = [] bboxes = [] with open(label_file, 'r') as fr2: for line2 in fr2.readlines(): data = line2.strip().split(' ') labels.append(int(data[0])) # x, y, w, h = float(data[1]), float(data[2]), float(data[3]), float(data[4]) bboxes.append([float(data[2]), float(data[1]), float(data[2]) + float(data[4]), float(data[1]) + float(data[3])]) gt_labels[name_body] = labels gt_bboxes[name_body] = bboxes image_ids.append(name_body) print("bboxes ", bboxes) print("image_ids ", name_body) return gt_labels, gt_bboxes, image_ids def merge_detection_results(model_file, results_dir, merged_results_file, merge_as_json=False): """ Merge all detection results produced by label_image into a single file. :param model_file: the model used to run label_image :param results_dir: the directory that contains all detection results (usually the output directory of the ipu_driver project) :param merged_results_file: the single merged results file :param merge_as_json: :return: merged_results_file """ model_file_name = os.path.basename(model_file) count = 0 if merge_as_json is True: assert(merged_results_file.split('.')[-1] == 'json') merged_txt = merged_results_file.replace('.json', '.txt') else: merged_txt = merged_results_file with open(merged_txt, 'w') as fw_txt: for result in sorted(os.listdir(results_dir)): if 'detection_' + model_file_name not in result: continue result_file = os.path.join(results_dir, result) with open(result_file, 'r') as fr_txt: for line in fr_txt.readlines(): new_line = line.strip()[1:-2] fw_txt.write(new_line + '\n') count += 1 print('{} detection results are merged.'.format(count)) if merge_as_json is True: with open(merged_results_file, 'w') as fw_json: with open(merged_txt, 'r') as fr_txt: lines = fr_txt.readlines() for i, line in enumerate(lines): if i == 0: new_line = '[{' + line.strip() + '},\n' elif i == len(lines) - 1: new_line = '{' + line.strip() + '}]\n' else: new_line = '{' + line.strip() + '},\n' fw_json.write(new_line) def voc2012_evaluation( output_dir, dataset_dir, model_file, merged_results_file=None, metric='mAP', verbose=False ): """ This function is used to evaluate detection models that are trained on 20-class voc datasets. :param output_dir: a directory containing all detection results :param merged_results_file: :param model_file: :param dataset_dir: root of the val2012 dataset :param metric: mAP or mIOU :param verbose: :return: mAP or mIOU """ if metric.lower() == 'map': gt_labels_dict, gt_bboxes_dict, image_ids = get_val2012_gt(voc2012_val_sgs_root=dataset_dir) print("lables_dict") print(gt_labels_dict) model_file_name = os.path.basename(model_file) if merged_results_file is None: merged_results_file = os.path.join(os.curdir, 'merged_results_{}.txt'.format(model_file_name)) merge_detection_results( model_file=model_file, results_dir=output_dir, merged_results_file=merged_results_file ) gt_labels = [] gt_bboxes = [] pred_bboxes = [] pred_labels = [] pred_scores = [] if verbose: print('Preparing groundtruth labels and detection results') count_boxes = 0 if merged_results_file.split('.')[-1] == 'json': print('json') detection_data = json.load(open(merged_results_file, 'r')) for i, image_id in enumerate(image_ids): gt_labels.append(np.asarray(gt_labels_dict[str(image_id)])) gt_bboxes.append(np.asarray(gt_bboxes_dict[str(image_id)])) bboxes = [] labels = [] scores = [] for d in detection_data: if d['image_id'] == image_id: xmin, ymin, width, height = d['bbox'][0], d['bbox'][1], d['bbox'][2], d['bbox'][3] bboxes.append([ymin, xmin, ymin + height, xmin + width]) labels.append(d['category_id']) scores.append(d['score']) count_boxes += 1 pred_bboxes.append(np.asarray(bboxes)) pred_labels.append(np.asarray(labels)) pred_scores.append(np.asarray(scores)) if (i + 1) % 500 == 0 or (i + 1) == len(image_ids): print('{}/{}'.format(i+1, len(image_ids))) else: print('not json') for i, image_id in enumerate(image_ids): gt_labels.append(np.asarray(gt_labels_dict[str(image_id)])) gt_bboxes.append(np.asarray(gt_bboxes_dict[str(image_id)])) bboxes = [] labels = [] scores = [] with open(merged_results_file, 'r') as fr_txt: for line2 in fr_txt.readlines(): detection_image_id = line2.strip().split(',')[0].split(':')[-1] if int(detection_image_id) == image_id: count_boxes += 1 bbox = line2.strip().split(', ')[2].split(':')[-1][1:-1].split(',') xmin, ymin, width, height = float(bbox[0]), float(bbox[1]), float(bbox[2]), float(bbox[3]) # bboxes.append([xmin, ymin, width, height]) bboxes.append([ymin, xmin, ymin+height, xmin+width]) # Note that the category id produced by label_image has a +1 bias to the original voc label. # Therefore, we should subtract it by 1 to get back the correct category id. category_id = int(line2.strip().split(', ')[1].split(':')[-1]) - 1 labels.append(category_id) score = float(line2.strip().split(':')[-1][0:-2]) scores.append(score) pred_bboxes.append(np.asarray(bboxes)) pred_labels.append(np.asarray(labels)) pred_scores.append(np.asarray(scores)) if verbose: if (i + 1) % 1000 == 0 or (i + 1) == len(image_ids): print('{}/{}'.format(i+1, len(image_ids))) if verbose: print('Total number of detected boxes: {}'.format(count_boxes)) if verbose: print('Run voc evaluation') voc_results = eval_detection_voc( pred_bboxes=pred_bboxes, pred_labels=pred_labels, pred_scores=pred_scores, gt_bboxes=gt_bboxes, gt_labels=gt_labels, gt_difficults=None, iou_thresh=0.5, use_07_metric=False ) print('\033[35mAP: {}\033[0m'.format(voc_results['map'])) if verbose: for i in range(len(voc_cfg.classes)-1): print('{}: {}'.format(voc_cfg.classes[i+1], voc_results['ap'][i])) return voc_results['map'] else: assert metric.lower() == 'miou' import cv2 mious = [] ious = [] num_classes = len(voc_cfg.classes) if verbose: print(num_classes) for i in range(num_classes): ious.append([]) count_images = 0 num_images = len(os.listdir(output_dir)) for segm_results in sorted(os.listdir(output_dir)): image_id = int(str(segm_results.split('_')[-1]).split('.')[0]) gt_file = os.path.join(dataset_dir, 'labels', str(image_id) + '.png') assert os.path.isfile(gt_file) gt_label = cv2.imread(gt_file, cv2.IMREAD_UNCHANGED) # image_name = segm_results.split('_')[-1][:-4] # image_file = os.path.join(dataset_dir, 'JPEGImages', image_name) # image = cv2.imread(image_file, cv2.IMREAD_UNCHANGED) height, width = gt_label.shape[0], gt_label.shape[1] resize_ratio = 513.0 / max(height, width) resized_height = int(resize_ratio * height) resized_width = int(resize_ratio * width) aligned_segm = [] data_start = 4 with open(os.path.join(output_dir, segm_results), 'r') as fr: lines = fr.readlines() lines_2 = lines[2] if(lines_2.find("Alignment") == -1): segm_shape_str = lines[2].split(',')[1] segm_shape_str = segm_shape_str.split('[')[-1].split(']')[0] segm_shape = [int(s) for s in segm_shape_str.split(' ')] assert segm_shape == [1, 513, 513] aligned_shape = segm_shape data_start = 4 else: [segm_shape_str, aligned_shape_str] = lines[2].split(',')[1:3] segm_shape_str = segm_shape_str.split('[')[-1].split(']')[0] aligned_shape_str = aligned_shape_str.split('[')[-1].split(']')[0] segm_shape = [int(s) for s in segm_shape_str.split(' ')] aligned_shape = [int(s) for s in aligned_shape_str.split(' ')] assert segm_shape == [1, 513, 513] assert aligned_shape[0] == 1 data_start = 5 for i in range(data_start, len(lines)): data = lines[i].strip().split(' ') for d in data: try: aligned_segm.append(int(float(d))) except: pass # print(d) aligned_segm = np.asarray(aligned_segm, dtype=np.uint8) if 'float.sim' in model_file: aligned_segm = aligned_segm[:513 * 513] aligned_segm = np.reshape(aligned_segm, (513, 513)) else: aligned_segm = np.reshape(aligned_segm, (aligned_shape[1], aligned_shape[2])) aligned_segm = aligned_segm[:, :513] cropped_segm = np.zeros((resized_height, resized_width), dtype=np.uint8) # for i in range(cropped_segm.shape[0]): # for j in range(cropped_segm.shape[1]): # cropped_segm[i, j] = aligned_segm[513 - resized_height + i, j] # if aligned_segm[513 - resized_height + i, j] > 0: # print(cropped_segm[i, j]) cropped_segm[:, :] = aligned_segm[(513 - resized_height):, (513 - resized_width):] dt_segmentation = cv2.resize(cropped_segm, (gt_label.shape[1], gt_label.shape[0]), interpolation=cv2.INTER_LINEAR) dt_segmentation = dt_segmentation.astype(np.uint8) # colorized_segm = np.zeros((dt_segmentation.shape[0], dt_segmentation.shape[1], 3), dtype=np.uint8) # for i in range(3): # colorized_segm[:, :, i] = dt_segmentation[:, :] # for cls in range(len(voc_cfg.segmentation_colors)): # colorized_segm = np.where(colorized_segm == cls, voc_cfg.segmentation_colors[cls], colorized_segm) # cv2.imshow('tflite segm', colorized_segm.astype(np.uint8)) # cv2.waitKey(0) # cv2.destroyAllWindows() for cls in range(num_classes): if cls in gt_label: ious[cls].append(compute_segm_iou(dt_segmentation, gt_label, cls=cls)) count_images += 1 if count_images % 100 == 0: print('{}/{}'.format(count_images, num_images)) for cls in range(num_classes): iou = np.asarray(ious[cls]) if len(iou) == 0: mious.append(np.array([0, 0])) else: mious.append(np.array([np.sum(iou) / len(iou), len(iou)])) mious = np.asarray(mious) mIOU = np.mean(mious[:, 0]) print('mIOU: {}'.format(mIOU)) if verbose: print('IOUs per class:', mious[:, 0]) # print('mIOU over 20 classes:', np.mean(mious[1:, 0])) return mIOU def parse_args(): import argparse parser = argparse.ArgumentParser( description='Computing VOC Metrics: python3 voc2012_evaluation.py \ --output_dir=output --dataset_dir=dataset --model_file=model' ) parser.add_argument( '--output_dir', dest='output_dir', type=str ) parser.add_argument( '--dataset_dir', dest='dataset_dir', type=str ) parser.add_argument( '--model_file', dest='model_file', type=str ) return parser.parse_args() if __name__ == '__main__': args = parse_args() mmAP = voc2012_evaluation( output_dir=args.output_dir, dataset_dir=args.dataset_dir, model_file=args.model_file, verbose=True)